표를 분산하는 것을 통해 중복을 제거할 수 있다.
표를 만들 때 지침으로 삼아야 할 말
모든 표는 하나의 테마(주제)만 가져야 한다.
--> 합쳤을 때의 정보가 다른 테이블에서도 사용되는 경우 누군가를 분가시킬 타이밍이다
그렇다고 해서 테이블에 모든 정보가 다 있는게 안좋은 게 아니다.
두가지 방법의 장점과 단점을 합해 사용하기 위해 나온것이 JOIN 이다.
실습 준비)
좋은 부품 만들기 = 쪼개기
LEFT OUTER JOIN : 왼쪽에만 있는 정보도 출력하는 것 (가장 인기 O)
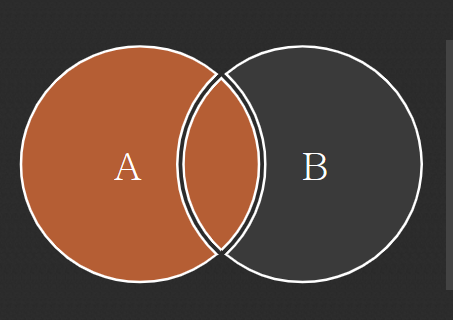
가장 많이 사용하는 이유
- A라는 정보만 가져올때, B에는 없는 경우가 많기 때문에 사용
ex)

INNER JOIN : LEFT, RIGHT, FULL 없으면 INNER JOIN 과 같다.

- INNER JOIN은 교집합이기 때문에 NULL값이 없다.
- 양쪽 다 해당되는 데이터 SELECT
- INNER JOIN으로 할 수 없는 것은 LEFT OUTER JOIN을 쓴다.
ex)

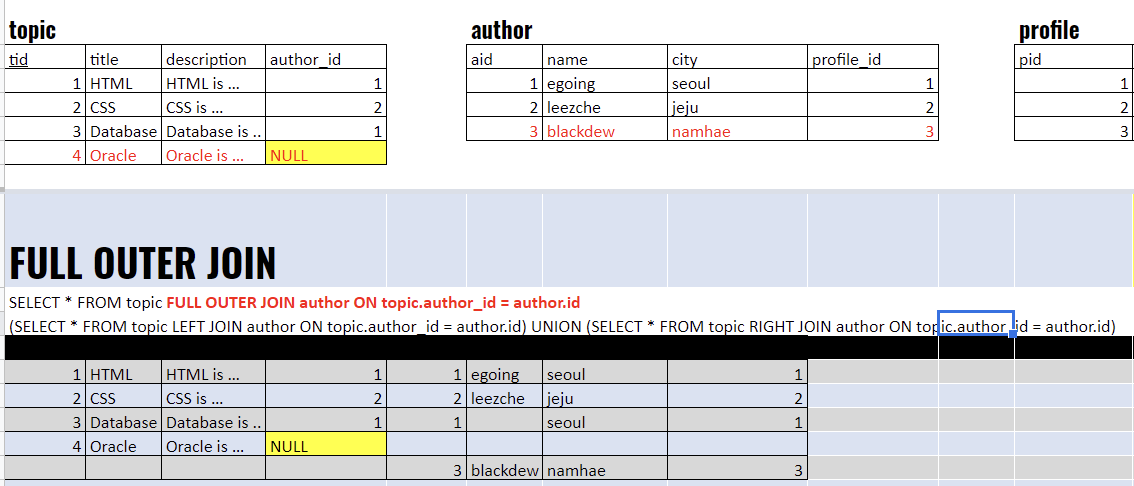
FULL OUTER JOIN : 왼쪽과 오른쪽에 있는 행 모두를 합성해서 하나의 표를 만드는 방법

- 합집합과 같음 (LEFT JOIN과 RIGHT JOIN을 합한 것)
- FULL OUTER JOIN에 대해 지원하지 않는 데이터베이스도 많다.
그럴땐 LEFT OUTER JOIN UNION RIGHT OUTER JOIN으로 SELECT 한다.
--> UNION은 DISTINCT(중복제거) 라는 단어를 생략하고 있는데, 중복된 결과 하나만 출력한다.
ex)
EXCUSIVE LEFT JOIN : A에만 존재하는 것만 가져와 하나의 표를 만드는 방법
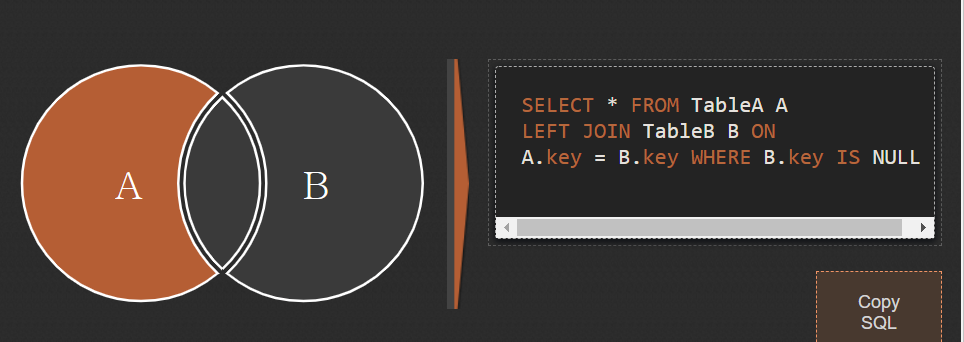
- SELECT * FROM topic LEFT JOIN author ON topic.author_id = author.aid WHERE author.aid is NULL

ex)

LEFT OUTER JOIN, INNER JOIN가 가장 중요하고 개념만 잘 가지고 있으면 쓸 데가 가장 많고,
나머지는 도출해 낼 수 있는 방법이라고 생각하자.
분해가 잘 되어 있어야 결합하기도 쉽다.
어떻게 테이블을 분해하는 것이 좋을 지는 데이터베이스 모델링, 정규화(normalization) 과 같은 주제를 통해서 접할 수 있다.
'생활코딩 > DATABASE' 카테고리의 다른 글
| 6) DATABASE : 관계형 데이터 모델링 (0) | 2020.07.28 |
|---|